When "Build Once, Serve Many" Breaks: Why AI Products Need Different Cost Models

I’ve built the AI Teaching Assistant prototype that identifies at-risk students and generates personalized quizzes. The technical work was straightforward: risk scoring algorithms, Claude API integration, FastAPI backend. Standard product development.
Now let’s figure out what it would cost to run in production.
The Traditional SaaS Model
I've spent more than 15 years building software products. The economic model was always the same:
High fixed costs → Near-zero marginal costs → High margins at scale
When you build a SaaS product, your unit economics probably looks like this:
- Engineering: $2M to build the platform
- Infrastructure: $5K/month for 100 customers
- Infrastructure: $15K/month for 10,000 customers
- Marginal cost per customer: ~$1/month
The beautiful part: once you built it, serving customer #1 cost the same as serving customer #10,000. Your gross margins improved as you scaled because fixed costs spread across more revenue.
This is the SaaS dream. Build once, serve many, money flows.
The AI System
My Teaching Assistant uses Claude's API to generate personalized quizzes. Simple feature. Configure the prompts, set up the RAG pipeline, test with some sample questions. Works great.
But when you do the math on what it would cost to run:
Per quiz generation:
- System prompt: 300 tokens
- Course content retrieval: 1,500 tokens
- Student performance data: 200 tokens
- Generated quiz: 1,500 tokens output
Cost per quiz: $0.029
For a single student taking two practice quizzes: $0.058
For 100 students in a pilot course: $5.80
For 5,000 students across 50 courses: $290/month
Wait. If my infrastructure costs are $200/month, my AI costs will be exceeding my entire hosting bill.
And this was just ONE feature.
And I also need to build:
- RAG-powered student chat (~$0.017 per message)
- Intervention message generation (~$0.004 per intervention)
- Risk scoring (negligible cost, just math)
My beautiful "build once, serve many" SaaS product had turned into "build once, pay per interaction."
The Fundamental Difference
Traditional SaaS: Fixed costs dominate
- Run: $10/month for 10 users, $100/month for 10,000 users
- Marginal cost: ~$0.01 per user
AI-powered SaaS: Variable costs matter
- Run: $50/month for 10 users, $5,000/month for 10,000 users
- Marginal cost: ~$0.50 per user
The difference: Every AI interaction costs real money.
This isn't a small nuance. This changes everything about how you:
- Price your product
- Model your unit economics
- Forecast your margins
- Optimize for profitability
- Make technology decisions
What Makes AI Cost Modeling Different
1. Token Economics Replace Seat Licensing
Traditional SaaS:
- You pay: Per seat/per user
- Cost scaling: Linear with users
- Predictability: High (you know your user count)
AI SaaS:
- You pay: Per token processed
- Cost scaling: Non-linear (depends on usage intensity)
- Predictability: Low (users behave differently)
Real example from my Teaching Assistant:
Same "seat" but different costs:
- Quiet student (2 chat messages, 1 quiz): $0.07/month
- Active student (20 chat messages, 5 quizzes): $0.48/month
- 7x difference in cost for the same "user"
Traditional SaaS pricing: "$10/student/month".
AI SaaS reality: "Depends which students".
2. Context Windows Are Hidden Cost Drivers
The biggest discovery: most of the cost is not the user's question or the AI's answer. It is the context.
Anatomy of one chat message cost:
System prompt: 500 tokens ($0.0015)
RAG retrieved content: 2,500 tokens ($0.0075) ← This
Conversation history: 1,000 tokens ($0.0030) ← And this
User question: 100 tokens ($0.0003)
AI response: 400 tokens ($0.0060)
─────────────────────────────────────────────
TOTAL: 4,500 tokens ($0.0183)
The user types 100 tokens. But I pay for 4,500 tokens.
Why this matters: You can't just count user queries. You need to model:
- How long is your system prompt?
- How much context are you retrieving?
- How much conversation history are you keeping?
- How long are typical responses?
Every one of these is an optimization lever. But first, you need to know the baseline.
3. Output Costs More Than Input
Claude pricing:
- Input: $3 per million tokens
- Output: $15 per million tokens
Output is 5x more expensive.
This flips traditional optimization thinking. In regular software, you optimize for compute efficiency. In AI products, you optimize for response brevity.
So optimization looks like:
Before:
- Prompt: "Explain this concept to the student in detail"
- Average response: 800 tokens
- Cost per response: $0.012
After:
- Prompt: "Explain in 2-3 sentences (under 100 tokens)"
- Average response: 80 tokens
- Cost per response: $0.0024
5x cost reduction just by constraining output length.
4. Model Selection Matters More Than You Think
I compared costs for quiz generation:
Claude Haiku 4.5 (cheapest, fast):
- Input: $0.25 per million tokens
- Output: $1.25 per million tokens
- Cost per quiz: $0.004
Claude Sonnet 4 (balanced):
- Input: $3 per million tokens
- Output: $15 per million tokens
- Cost per quiz: $0.029
Claude Opus 4.1 (maximum capability):
- Input: $15 per million tokens
- Output: $75 per million tokens
- Cost per quiz: $0.143
36x difference between cheapest and most expensive.
For 1,000 students taking 2 quizzes each:
- Haiku: $8/month
- Sonnet: $58/month
- Opus: $286/month
The question isn't just "which is cheapest?" It's "which is cheap enough for acceptable quality?"
I needed to see all the options side-by-side with real usage scenarios. Excel couldn't handle the multi-variable complexity, so I built a calculator to model these economics systematically.
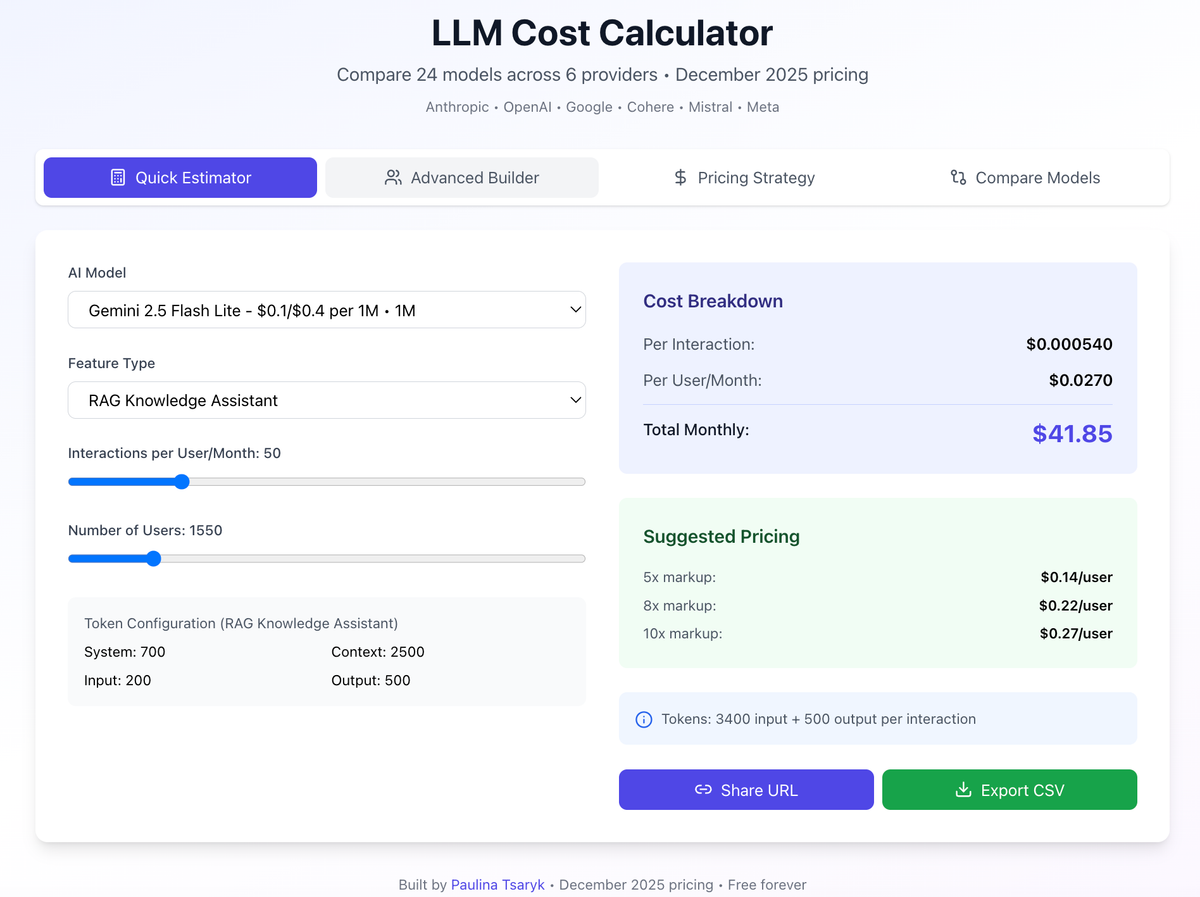
Here Comes The Cost Calculator
Built it in ~6 hours with Claude's help. Single HTML file with 24 models across 6 providers (December 2025 pricing). No backend, no tracking, works offline.
This is what it can do.
1. Quick Estimator with Realistic Presets
The first time I tried modeling costs, I spent 30 minutes just deciding: How many tokens is a "typical" RAG query? Should I count system prompts? What about conversation history?
So I built 7 preset scenarios with realistic token estimates:
- Simple chatbot: 800 input / 200 output
- RAG knowledge assistant: 3,400 input / 600 output
- Document analyzer: 11,000 input / 2,000 output
- Code generator: 1,500 input / 800 output
- Creative writing: 1,000 input / 1,500 output
- Data analyst: 5,000 input / 1,200 output
- Quiz generator: 2,000 input / 1,500 output
Now I could start with "I'm building a RAG assistant" and immediately see costs across all providers — no guesswork on token counts.
2. User Segmentation, Not Just "Average User"
Advanced Builder that models user distribution. Real usage isn't uniform. It will probably look like:
- 60% light users (10 interactions/month)
- 30% medium users (50 interactions/month)
- 10% heavy users (200 interactions/month)
Example:
- "Average" calculation: 50 interactions/month → $0.915/user
- Segmented calculation: 60/30/10 mix → $0.619/user
Difference: 32% in your cost projections.
Traditional SaaS: Doesn't matter, they all pay the same. AI SaaS: Heavy users cost you 20x more
3. Provider Comparison That Shows Trade-offs
The most valuable feature: compare models side-by-side with percentage differences.
Real comparison I ran:
Comparing for my RAG chatbot (3,400 input / 600 output tokens):
Gemini was 95% cheaper than Claude.
But the calculator also showed me:
- Gemini has 1M context window (vs Claude's 200K)
- This lets me include more course content
- Which might improve quiz quality
- Which might offset any quality drop from cheaper model
Gemini isn’t just 95% cheaper—it actually might be better for quiz generation.
Why? That 1M context window (vs Claude's 200K) means I can include the entire course syllabi instead of chunked excerpts. The "cheaper" model might produce higher quality output because it has access to more complete context.
This is where cost modeling gets interesting. The optimization isn't "find the cheapest model." It's "find the model where cost and capability intersect optimally for this specific use case."
The decision: Use Gemini for quiz generation (cost-sensitive), keep Claude for personalized interventions (quality-sensitive).
4. Pricing Strategy Built In
Knowing costs is half the battle. The other half: "How do I price this?"
Three pricing approaches:
Cost-Plus:
- Your cost: $0.62/user/month
- 10x markup: $6.20/user/month
- Quick and safe, but might leave money on table
Value-Based:
- Customer alternative: $50/user/month (human tutoring)
- Your price: $20/user/month (60% savings for them)
- Your margin: 97%
- Captures value created, not just cost
Margin-Based:
- Target margin: 80%
- Required price: $3.10/user/month
- Minimum viable price to hit target
For my Teaching Assistant, this showed:
- I could charge $20/month per student
- My cost was $0.62/month per student
- Margin: 97%
- But tutoring costs $50-80/hour
This validates the business model in under a minute.
Three Things I Underestimated
- Context is 80% of your cost
I thought I am paying for AI responses. Turns out I would be paying mostly for the context I'm sending to the AI. System prompts, RAG retrievals, conversation history — that's where the money goes.
- Heavy users cost 20x more than light users
In SaaS, all users cost the same. In AI SaaS, your power users can bankrupt you. I have to model usage distribution, not averages.
- The expensive model might actually be cheaper
Opus costs 36x more per query than Haiku. But if Opus gives the right answer in one shot while Haiku needs three tries, Opus is cheaper. Quality affects costs.
What I Learned Building This
AI Products Need Different Financial Discipline
In traditional SaaS, you build the feature first, then figure out infrastructure costs and revisit quarterly. With AI, that's backwards - model costs before every feature, monitor continuously.
New workflow: model costs → validate quality threshold → then build.
Optimization Is Continuous, Not One-Time
Every prompt tweak changes costs:
- Shorten system prompt: -15% cost
- Reduce conversation history: -25% cost
- Constrain output length: -40% cost
- Switch to cheaper model: -90% cost
Use The Right Model for the Job
Don’t use "one model for everything", use model that does the best job for your task:
- Haiku for simple classification (12x cheaper)
- Sonnet for quality-sensitive features (baseline)
- Opus only for truly complex reasoning (5x more expensive)
The Bigger Lesson
AI products break traditional SaaS economics. Variable costs matter again.
This isn't necessarily bad. It just means:
- You need different financial models
- You need tighter cost discipline
- You need to optimize continuously
- You need to price based on value
The successful AI products won't just be the ones with the best models. They'll be the ones that figure out which models to use where, and optimize the economics without sacrificing the outcomes that matter.
And you can't optimize what you don't measure.
Building an AI product? Try the calculator at https://was1paulina.github.io/llm-calculator/ or fork it on GitHub and customize for your use case.
What's your biggest surprise about AI product costs? I'm collecting 'oh shit' moments from other builders — the things you didn't realize until you tried to model it.