What Could Go Wrong? Building Resilient AI Systems

I spent last week trying to think of ways to break (aka improve) my AI Teaching Assistant. That's probably my QA experience talking.
And no, that's not because I enjoy chaos, but because building a working demo is the easy part. The hard part is figuring out what happens when things inevitably go wrong in production.
With traditional software, you handle errors once and you're mostly done. API returns an error code? Retry a few times. Network timeout? Show an error message. Server down? Fail over to backup. Standard playbook.
AI systems don't work like that.
The Problem
So I was mapping out what it would take to move my prototype from "works on my laptop" to "works for actual students" and hit an immediate question: what happens when the Claude API call fails?
Simple question. Turns out the answer isn't simple at all.
Because unlike a traditional API where you get a clear success or failure, AI systems give you a spectrum. The call might succeed but the response could be wrong. It might be slow. It might hallucinate facts. It might cost way more than expected. And all of these are different kinds of failures that need different handling strategies.
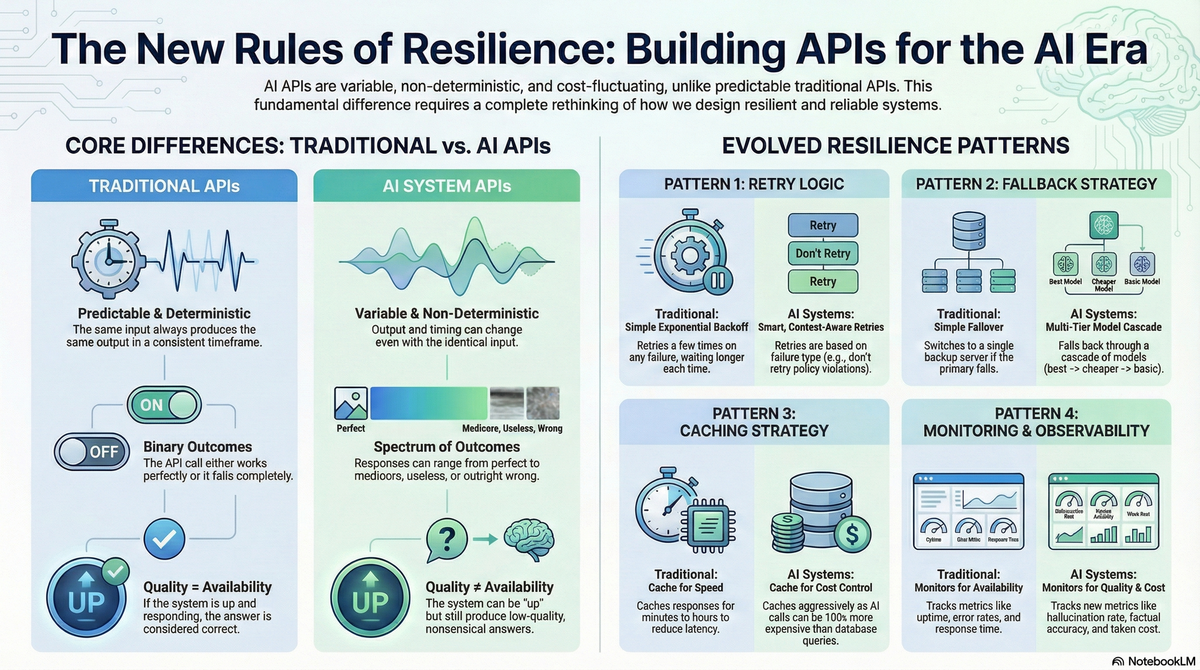
How Traditional APIs Work
Traditional APIs are predictable. Same input, same output, every time. Call happens in milliseconds. Either you get a valid response or you get an error code. That's it.
When something goes wrong, the failure modes are clear:
- Network error: Retry immediately
- 500 error: Wait a bit, retry
- Rate limit: Back off for a few seconds
- Authentication failure: Don't retry, just fail
And once it works, you're done. The response is correct because it's deterministic.
How AI APIs Actually Work
AI APIs are fundamentally different. They're non-deterministic - same input can produce different outputs. Timing varies from seconds to minutes depending on complexity. And most importantly: a successful API call doesn't mean you got a useful response.
The system can return HTTP 200 OK and still give you garbage. A quiz question that doesn't match the course material. An explanation that's technically correct but incomprehensible. An answer that sounds confident but is completely wrong.
With traditional APIs, availability equals quality. If it responds, the answer is correct.
With AI APIs, the system can be "up" and still be useless.
What This Means for Resilience
Building resilient AI systems requires rethinking every standard pattern:
Retry Logic
Traditional approach: Exponential backoff. Try again in 1 second, then 2, then 4, then 8. Works great when the problem is temporary network congestion.
AI reality: You need to know why it failed before deciding whether to retry.
- Rate limit: Don't retry in seconds, these limits reset in minutes or hours
- Content policy violation: Don't retry at all - same input will fail again
- Context too long: Must modify the input before retrying, not just wait
- Response quality issue: Might need to retry with a different model or parameters
The failure type determines the strategy.
Fallback Strategies
Traditional approach: Fail over to backup server. Both servers do the same thing.
AI reality: Multi-tier cascade where each tier accepts different quality/cost tradeoffs.
For the Teaching Assistant:
- Primary: Claude Opus (best quality, expensive, sometimes slow)
- Secondary: Claude Sonnet (good quality, cheaper, faster)
- Tertiary: Llama or Mistral (acceptable quality, very cheap, fast)
- Emergency: Pre-generated template questions or cached responses
You don't get the same quality at each tier, but partial functionality beats total failure.
Caching
Traditional approach: Cache for a few minutes to reduce database load. Moderate hit rates are fine.
AI reality: Cache aggressively because AI calls cost 10-100x more than database queries.
For my Teaching Assistant, if 50 students all ask for a quiz on the same algebra topic, I should generate it once and serve the rest from cache. Target cache hit rates of 40-60%+ instead of the 10-20% typical for traditional systems.
Cache keys need to include prompt hash, model version, and parameters. And responses can often be cached for hours or days, not minutes.
Monitoring
Traditional approach: Track response time, error rate, uptime. If it's up and fast, you're good.
AI reality: Being up and fast doesn't mean it's working correctly.
You need to monitor:
- Quality metrics: Is the AI hallucinating? Are responses relevant? Are they actually correct?
- Cost metrics: Tokens per request, cost per user, budget burn rate
- Model performance: How often are you falling back to cheaper models?
- Safety metrics: Content policy violations, prompt injection attempts
Success isn't "fast response with no error code." It's "acceptable quality at reasonable cost in reasonable time."
And you often need human sampling to validate the automated metrics because detecting when an AI answer is subtly wrong is hard.
What I Built
Theory is useful, but implementation is where you learn what actually matters.
For my Teaching Assistant, I focused on three resilience patterns:
1. Smart Retry with Exponential Backoff
The service automatically retries failed API calls, but intelligently:
- Retries connection errors and server errors (500, 502, 503, 504)
- Uses exponential backoff with jitter (prevents thundering herd)
- Doesn't retry authentication errors or content violations
- Maximum 3 attempts before giving up
This handles temporary issues without wasting API calls on permanent failures.
2. User-Friendly Error Messages
Every technical error gets translated to something students actually understand:
No stack traces. No "Error 429: Rate limit exceeded on endpoint /v1/messages." Just clear guidance on what to do next.
3. Automatic Fallback to Local Questions
When Claude API is completely unavailable - maybe it's down, maybe I hit my budget limit, maybe there's a network issue - the system seamlessly falls back to pre-generated questions.
Students still get practice quizzes on Linear Equations, Quadratics, Polynomials, Factoring. The questions aren't personalized to their specific course, but they're mathematically correct and include explanations.
Degraded functionality beats no functionality.
What I Learned
The biggest insight: AI systems add quality and cost as failure dimensions alongside availability and latency.
With traditional software, you optimize for speed and uptime. With AI systems, you're constantly balancing four variables:
- Speed: How fast does it respond?
- Availability: Is it working at all?
- Quality: Is the response actually useful?
- Cost: What's this costing per user?
And unlike traditional systems where you fix these once during development, AI systems require ongoing monitoring and adjustment. Model quality can degrade. Costs can spike. What worked yesterday might not work today.
Why This Matters
Building prototypes is easy - they work from known predefined mock data and if the AI is completely down, waiting a few minutes is fine.
But imagine building AI features where quality degradation isn't acceptable. Medical diagnosis. Financial advice. Legal document analysis. The resilience patterns become much more complex.
The architectural patterns are similar to traditional software (retry logic, fallbacks, circuit breakers, caching), but the evaluation criteria are fundamentally different. You're not just checking "did it return HTTP 200?" You're checking "did it return something useful?"
That's the gap between building demos and building production AI systems.
The Code
All the error handling is implemented in the Claude service layer. The retry logic, fallback mechanism, and user-friendly error messages are documented in detail here: ERROR_HANDLING.md
If you're building AI features and wondering how to handle failures beyond "show an error message and hope it works next time," the patterns are there.
What's Next
This post covered API resilience - handling failures when they happen. But in production AI systems, you need to know when things are going wrong before users notice.
Next: monitoring and observability for AI systems. How do you detect when your AI feature is slowly degrading in quality? How do you track costs before they explode? What metrics actually matter?
If you're building AI products and have fought these battles yourself, I'd love to hear what patterns actually worked for you in production. What did I miss? What looks good in theory but breaks in practice?
GitHub: AI Teaching Assistant Prototype