The Quiz Looks Fine Until It’s Not: Why AI Systems Need Different Monitoring

Last week, I wrote about what could go wrong with my AI Teaching Assistant - API failures, cost explosions, bad outputs, and data privacy concerns. I focused on building resilience: error handling, fallbacks, and safety checks.
But here's what I didn't address: How would I even know if something went wrong?
My demo has basic error handling now. If Claude's API is down, I catch it. If a request fails, I retry it. But what if the API returns a successful response that's completely useless? What if quiz quality slowly degrades over time? What if I'm bleeding money on inefficient prompts?
Traditional monitoring tells me if my system is running. But for AI systems, I need to know if it's working well.
This led me down a research rabbit hole about AI system monitoring, and I realized: the whole paradigm is different. Here's what I learned.
What I Already Built (from last week's post):
- Error handling for API failures
- Retry logic with exponential backoff
- Fallback responses when Claude is unavailable
- Basic cost tracking
What Traditional Monitoring Would Show:
- API uptime: 99.9%
- Average response time: 200ms
- Error rate: 0.5%
- All requests completed successfully
The Problem: These metrics tell me my system is running. They don't tell me if the quiz it just generated is any good. They don't tell me if quiz quality is degrading. They don't tell me if I'm spending $10 per student when I should be spending $2.
Traditional monitoring answers: "Is it up?" AI monitoring needs to answer: "Is it working well?"
The Five Differences
1. Deterministic vs Probabilistic
Traditional software is deterministic: same input produces same output. You test it once, it works, you ship it. Monitoring is straightforward - did this request succeed? Yes or no.
AI systems are probabilistic. The same input can produce different outputs every time. You can't just check "did it work?" - you need to assess "how well did it work this time?"
For the Teaching Assistant, this means every quiz generation from the same syllabus could be different. One generation might produce clear, appropriately difficult questions with good concept coverage. The next might be too easy or have confusing wording. Both API calls return 200 OK. Both technically "worked."
What you'd need to monitor: Quality distribution over time. Track metrics like question clarity scores, difficulty calibration, concept coverage. Alert when too many outputs fall below threshold. You're not checking binary success - you're checking if the quality distribution stays consistent
2. Obvious vs Silent Failures
When traditional software fails, you know immediately. Logs throw errors, pages stop loading, alarms go off. A 500 error is obvious.
AI systems fail silently. The API returns 200 OK, the response looks properly formatted, but the content is wrong. The quiz might reference textbook chapters that don't exist, or generate questions completely off-topic, or produce nonsensical answer choices.
For the Teaching Assistant, a silent failure might look like: Quiz generates successfully, questions are grammatically correct, but they're about the wrong chapter. Or the difficulty level is completely miscalibrated - generating college-level questions for a high school syllabus. Or answer choices that are all technically correct, making the question impossible to answer.
Traditional monitoring would show: ✅ Request succeeded, ✅ Response generated, ✅ Zero errors.
What you'd need to monitor: Content validation checks (does this align with course materials?), hallucination detection (are citations real?), quality scoring (does this meet minimum standards?). You need to validate what was generated, not just that something was generated.
3. Static vs Drifting
Traditional software is static. The code you deployed yesterday is the same code running today. If it worked yesterday, it works today. Performance degrades gradually from increased load or data volume, but the behavior is predictable.
AI systems drift. Output quality can degrade without any code changes. Model behavior shifts, prompt effectiveness decays, data distributions change. What worked perfectly last month might produce worse results today.
For the Teaching Assistant, drift could manifest as: Quiz difficulty gradually becoming easier over time. Or certain topics generating consistently better questions than others, when they used to be equal. Or the quiz format slowly deviating from the template. All without any code deployments.
Traditional monitoring would show: ✅ Same code version, ✅ No deployments, ✅ System stable.
What you'd need to monitor: Baseline quality metrics established at launch, trend analysis comparing current performance to historical averages, automated alerts when quality drops below acceptable thresholds. You're not just monitoring current state - you're monitoring change over time.
4. Simple vs Proxy Metrics
Traditional software has direct metrics. API latency tells you exactly what users experience - is the page loading in 100ms or 2 seconds? Error rate tells you exactly how many requests are failing. These metrics directly measure the thing you care about.
AI systems require proxy metrics. How do you measure if a generated quiz is "good"? There's no single number that captures it. You need multiple signals: instructor ratings of question quality, student completion rates, whether students actually learn from the quiz, engagement with AI-generated hints. Each is an approximation, not a direct measurement.
For the Teaching Assistant, I can't just track "quiz generation success rate" and call it done. A successfully generated quiz might still be terrible. I'd need to track: Do instructors approve these questions? Do students find them helpful? Are the questions at appropriate difficulty? Does concept coverage match the syllabus? Are students more likely to complete AI-generated quizzes vs manual ones?
None of these perfectly measures "quiz quality" - they're all proxies. And crucially, automated metrics aren't enough. I'd need human evaluation: instructors reviewing sample quizzes, students providing feedback, outcome data showing if interventions actually help.
What you'd need to monitor: Multiple quality signals combined into a composite score, human review workflows integrated into monitoring, regular calibration of which proxies actually correlate with outcomes you care about.
5. Fixed vs Variable Costs
Traditional software has mostly fixed costs. You pay for servers, databases, CDN regardless of usage. Costs scale in steps - when you need more capacity, you add another server. But the cost per user request is essentially zero once infrastructure is provisioned.
AI systems have variable costs per interaction. Every quiz generated, every risk analysis run, every intervention message costs API tokens. More users = more API calls = directly higher costs. If quiz generation costs $0.10 and you have 1000 students generating 5 quizzes each, that's $500 in API costs alone. Scale to 10,000 students and you're at $5,000.
For the Teaching Assistant, this fundamentally changes what I need to monitor. It's not just "is the system healthy?" but "is this economically viable?" I need to track: cost per quiz generation vs cost per risk analysis vs cost per intervention. Which features are expensive? What does it cost per student per month? If I optimize prompts to use fewer tokens, how much do I save? At what student volume does this become unsustainable?
Cost monitoring becomes a product decision, not just an ops concern. Maybe quiz generation is too expensive and I need to cache common questions. Maybe certain intervention types cost 5x others - should I limit those? Traditional software doesn't have these per-interaction economic constraints.
What you'd need to monitor: Token usage broken down by feature, cost per student calculated and tracked over time, usage patterns to forecast scaling costs, cost-performance tradeoffs (cheaper prompts vs quality).
What This Means in Practice
So what does this actually look like? Here's what a complete monitoring system for the Teaching Assistant would need:
Traditional Metrics (Still Needed):
- API uptime and latency
- Error rates
- Request throughput
- Infrastructure health
AI-Specific Metrics (New Requirements):
Quality Metrics:
- Quiz quality scores (automated + human review)
- Question clarity ratings
- Difficulty calibration consistency
- Concept coverage distribution
Drift Detection:
- Quality trends over time
- Topic-specific performance changes
- Prompt effectiveness decay
- Output distribution shifts
Cost Metrics:
- Token usage per feature (quiz vs intervention vs risk scoring)
- Cost per student
- Cost per interaction type
- Usage pattern analysis
Content Validation:
- Hallucination detection rate
- Citation accuracy (when RAG is added)
- Content alignment with course materials
- Confidence calibration
Human Evaluation:
- Instructor feedback loop
- Student engagement with AI-generated content
- Intervention acceptance rates
- Actual outcome metrics (grade improvements)
The traditional metrics tell you the system is up. The AI metrics tell you it's producing value.
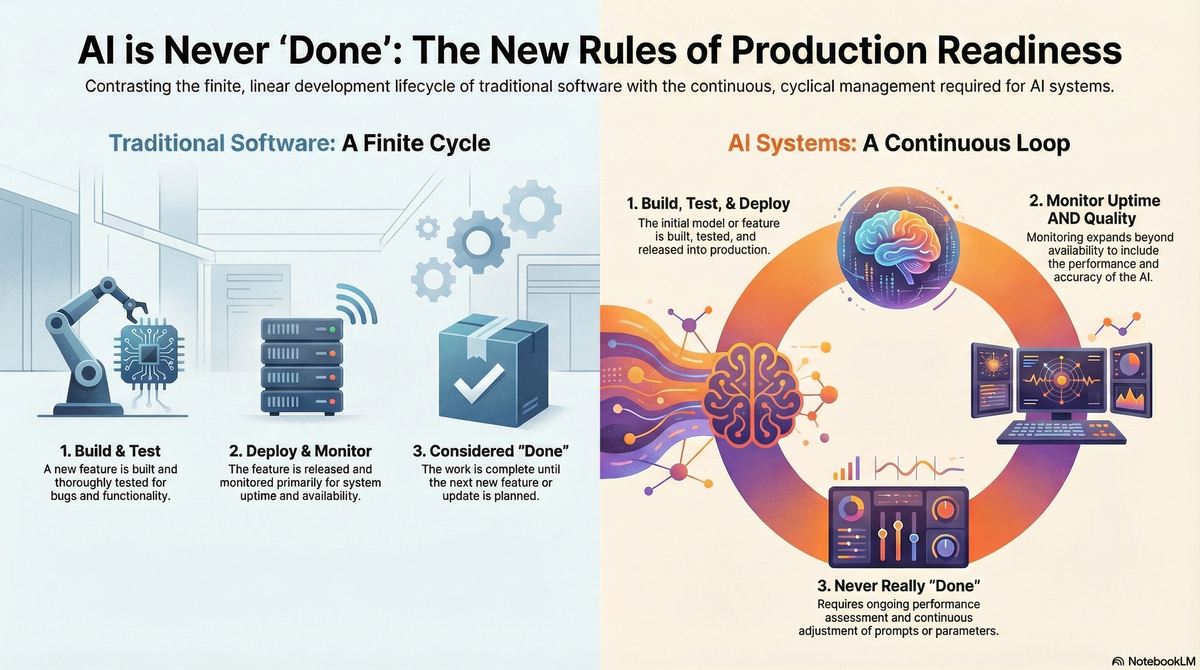
The Shift in What 'Production-Ready' Means
This changes the definition of done.
Traditional software:
- Build feature
- Test thoroughly
- Deploy
- Monitor uptime
- Done (until next feature)
AI systems:
- Build feature
- Test thoroughly
- Deploy
- Monitor uptime AND quality
- Continuously assess performance
- Adjust prompts/parameters based on metrics
- Never really 'done' - ongoing quality management
For the Teaching Assistant, 'production-ready' would mean:
- Deployed ✓
- Monitoring quality continuously ✓
- Detecting degradation automatically ✓
- Human review process in place ✓
- Cost tracking and optimization ✓
- Feedback loops established ✓
Traditional monitoring asks: 'Is it up?' AI monitoring asks: 'Is it working well - consistently, sustainably, without degrading?'
That's the shift from traditional PM to AI PM: from shipping features to maintaining quality in probabilistic systems.
What's your experience with AI system monitoring? What surprised you about the difference from traditional software?